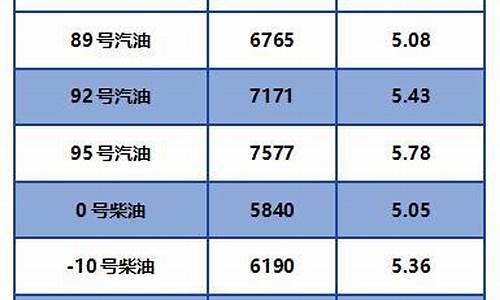
油价算法公式表最新版全文_油价算法公式表最新版全文
1.数据挖掘核心算法之一--回归

1. 中石油 中海油和中石化是类央企,以前给国家上交红利10%,2011年调整到上交15%。
2 其实在国内石油这块很多都是进行招标开发,就拿国内来说,早已经不只是3大油企垄断开发了,已经有很多外资企业,比如壳牌,美孚都有很多中标项目,比如2010年壳牌在四川地区中标的气田开发。对民营资本来说,中国从来都不禁止个人从事石油相关的买卖和生产。楼主不是石油行业的人吧,中国的私企石油公司实际上是非常多的,个人感觉做的最好的,比如北京的安东石油。而且2010中国的石油储备权,中标的6家油企,有3家是民营,而央企只有中石油和中石化,所以已经很大程度放开了~~为什么这些私企石油公司没有什么话语权呢,是因为它们没有足够的资本。石油行业是需要大量的钱的,随便一个油田的勘探开发至少都是上千亿人民币的投入,这对民营资本来说很天价~!
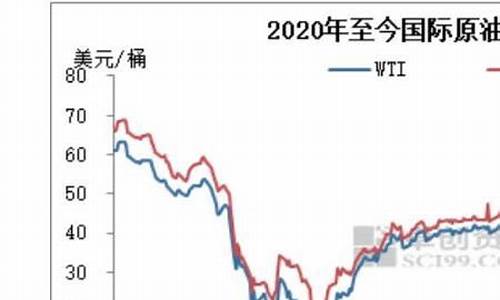
3,中石油中石化所谓的亏损这种说法是很无稽之谈的,原因是,首先要明白,国内一年消耗石油差不多4亿多吨,而中石油中石化等企业自己生产的只有2亿吨不到,也就是说,超过一半是靠进口,而现在国内有石油进口权的只有3家(虽说其实有进口权的一共有20多家,但只有这3家可以自由支配进口石油,其他全部要通过中石油和中石化排产炼化,不能自己支配),中石油中石化,还有中国兵器集团下面一家叫振华石油的石油公司。所以国际油价影响很大(这是国内几大石油商他们自己要涨价说法的依据),而中石油在国际原油市场一直是买涨弃跌的垃圾做法(原因不细说),再加上几大石油商要给国家很大比例的税费,最后还加上中国这种石油企业保赚不赔的成品油定价机制,就造就了高油价
4,这个问题,你的意思是指进口原油这块业务剥离么,上面我已经说很清楚了,不大可能剥离的,一是从供应上,二是从现在的和生产能力的布局上,三就是从中国的政治结构体制上
数据挖掘核心算法之一--回归
货物的运费,通常有两种算法:体积重量、路途、油价。
一种是按货物体积(适用于轻但体积大的货物),一种是按货物的重量(一般是体积不大但很重)
1、基本运费,基本运费=单位基本运费×整箱数
2、港口附加费,港口附加费=单位港口附加费×整箱数
3、燃油附加费,燃油附加费=单位燃油附加费×整箱数
拼箱装:拼箱运费只有基本运费,分按体积与重量计算两种方式
按体积计算,X1=单位基本运费(MTQ)×总体积
按重量计算,X2=单位基本运费(TNE)×总毛重
取 X1、X2 中较大的一个。教你如何计算海运运费:
扩展资料:
种类
运输价格按运输方式的不同,可以分为铁路运价、水运运价、汽车运价、航空运价和管道运输运价;按货物运载方式和要求的目的不同,可以分为整车运价和零担运价,
按运输距离远近的不同,可以分为长途运价、短途运价;根据国民经济决策和方针政策的需要,有特定运价、优待运价等。此外,依据运输特点和条件的不同,还有联运运价、专程运价、特种货物运价,以及区域运价等等。
百度百科-运费
数据挖掘核心算法之一--回归
回归,是一个广义的概念,包含的基本概念是用一群变量预测另一个变量的方法,白话就是根据几件事情的相关程度,用其中几件来预测另一件事情发生的概率,最简单的即线性二变量问题(即简单线性),例如下午我老婆要买个包,我没买,那结果就是我肯定没有晚饭吃;复杂一点就是多变量(即多元线性,这里有一点要注意的,因为我最早以前犯过这个错误,就是认为预测变量越多越好,做模型的时候总希望选取几十个指标来预测,但是要知道,一方面,每增加一个变量,就相当于在这个变量上增加了误差,变相的扩大了整体误差,尤其当自变量选择不当的时候,影响更大,另一个方面,当选择的俩个自变量本身就是高度相关而不独立的时候,俩个指标相当于对结果造成了双倍的影响),还是上面那个例子,如果我丈母娘来了,那我老婆就有很大概率做饭;如果在加一个,如果我老丈人也来了,那我老婆肯定会做饭;为什么会有这些判断,因为这些都是以前多次发生的,所以我可以根据这几件事情来预测我老婆会不会做晚饭。
大数据时代的问题当然不能让你用肉眼看出来,不然要海量计算有啥用,所以除了上面那俩种回归,我们经常用的还有多项式回归,即模型的关系是n阶多项式;逻辑回归(类似方法包括决策树),即结果是分类变量的预测;泊松回归,即结果变量代表了频数;非线性回归、时间序列回归、自回归等等,太多了,这里主要讲几种常用的,好解释的(所有的模型我们都要注意一个问题,就是要好解释,不管是参数选择还是变量选择还是结果,因为模型建好了最终用的是业务人员,看结果的是老板,你要给他们解释,如果你说结果就是这样,我也不知道问什么,那升职加薪基本无望了),例如你发现日照时间和某地葡萄销量有正比关系,那你可能还要解释为什么有正比关系,进一步统计发现日照时间和葡萄的含糖量是相关的,即日照时间长葡萄好吃,另外日照时间和产量有关,日照时间长,产量大,价格自然低,结果是又便宜又好吃的葡萄销量肯定大。再举一个例子,某石油产地的咖啡销量增大,国际油价的就会下跌,这俩者有关系,你除了要告诉领导这俩者有关系,你还要去寻找为什么有关系,咖啡是提升工人精力的主要饮料,咖啡销量变大,跟踪发现工人的工作强度变大,石油运输出口增多,油价下跌和咖啡销量的关系就出来了(单纯的例子,不要多想,参考了一个根据遥感信息获取船舶信息来预测粮食价格的真实案例,感觉不够典型,就换一个,实际油价是人为操控地)。
回归利器--最小二乘法,牛逼数学家高斯用的(另一个法国数学家说自己先创立的,不过没办法,谁让高斯出名呢),这个方法主要就是根据样本数据,找到样本和预测的关系,使得预测和真实值之间的误差和最小;和我上面举的老婆做晚饭的例子类似,不过我那个例子在不确定的方面只说了大概率,但是到底多大概率,就是用最小二乘法把这个关系式写出来的,这里不讲最小二乘法和公式了,使用工具就可以了,基本所有的数据分析工具都提供了这个方法的函数,主要给大家讲一下之前的一个误区,最小二乘法在任何情况下都可以算出来一个等式,因为这个方法只是使误差和最小,所以哪怕是天大的误差,他只要是误差和里面最小的,就是该方法的结果,写到这里大家应该知道我要说什么了,就算自变量和因变量完全没有关系,该方法都会算出来一个结果,所以主要给大家讲一下最小二乘法对数据集的要求:
1、正态性:对于固定的自变量,因变量呈正态性,意思是对于同一个答案,大部分原因是集中的;做回归模型,用的就是大量的Y~X映射样本来回归,如果引起Y的样本很凌乱,那就无法回归
2、独立性:每个样本的Y都是相互独立的,这个很好理解,答案和答案之间不能有联系,就像掷硬币一样,如果第一次是反面,让你预测抛两次有反面的概率,那结果就没必要预测了
3、线性:就是X和Y是相关的,其实世间万物都是相关的,蝴蝶和龙卷风(还是海啸来着)都是有关的嘛,只是直接相关还是间接相关的关系,这里的相关是指自变量和因变量直接相关
4、同方差性:因变量的方差不随自变量的水平不同而变化。方差我在描述性统计量分析里面写过,表示的数据集的变异性,所以这里的要求就是结果的变异性是不变的,举例,脑袋轴了,想不出例子,画个图来说明。(我们希望每一个自变量对应的结果都是在一个尽量小的范围)
我们用回归方法建模,要尽量消除上述几点的影响,下面具体讲一下简单回归的流程(其他的其实都类似,能把这个讲清楚了,其他的也差不多):
first,找指标,找你要预测变量的相关指标(第一步应该是找你要预测什么变量,这个话题有点大,涉及你的业务目标,老板的目的,达到该目的最关键的业务指标等等,我们后续的话题在聊,这里先把方法讲清楚),找相关指标,标准做法是业务专家出一些指标,我们在测试这些指标哪些相关性高,但是我经历的大部分公司业务人员在建模初期是不靠谱的(真的不靠谱,没思路,没想法,没意见),所以我的做法是将该业务目的所有相关的指标都拿到(有时候上百个),然后跑一个相关性分析,在来个主成分分析,就过滤的差不多了,然后给业务专家看,这时候他们就有思路了(先要有东西激活他们),会给一些你想不到的指标。预测变量是最重要的,直接关系到你的结果和产出,所以这是一个多轮优化的过程。
第二,找数据,这个就不多说了,要么按照时间轴找(我认为比较好的方式,大部分是有规律的),要么按照横切面的方式,这个就意味横切面的不同点可能波动较大,要小心一点;同时对数据的基本处理要有,包括对极值的处理以及空值的处理。
第三, 建立回归模型,这步是最简单的,所有的挖掘工具都提供了各种回归方法,你的任务就是把前面准备的东西告诉计算机就可以了。
第四,检验和修改,我们用工具计算好的模型,都有各种设检验的系数,你可以马上看到你这个模型的好坏,同时去修改和优化,这里主要就是涉及到一个查准率,表示预测的部分里面,真正正确的所占比例;另一个是查全率,表示了全部真正正确的例子,被预测到的概率;查准率和查全率一般情况下成反比,所以我们要找一个平衡点。
第五,解释,使用,这个就是见证奇迹的时刻了,见证前一般有很久时间,这个时间就是你给老板或者客户解释的时间了,解释为啥有这些变量,解释为啥我们选择这个平衡点(是因为业务力量不足还是其他的),为啥做了这么久出的东西这么差(这个就尴尬了)等等。
回归就先和大家聊这么多,下一轮给大家聊聊主成分分析和相关性分析的研究,然后在聊聊数据挖掘另一个利器--聚类。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。